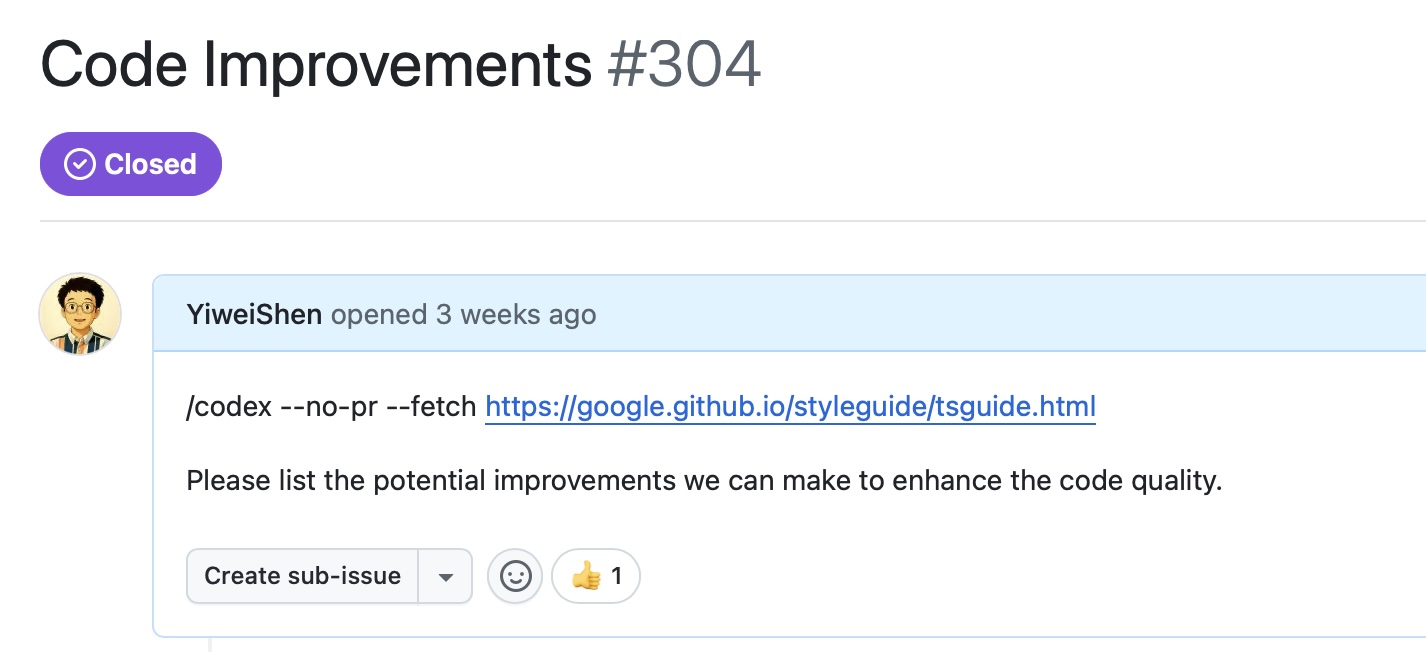
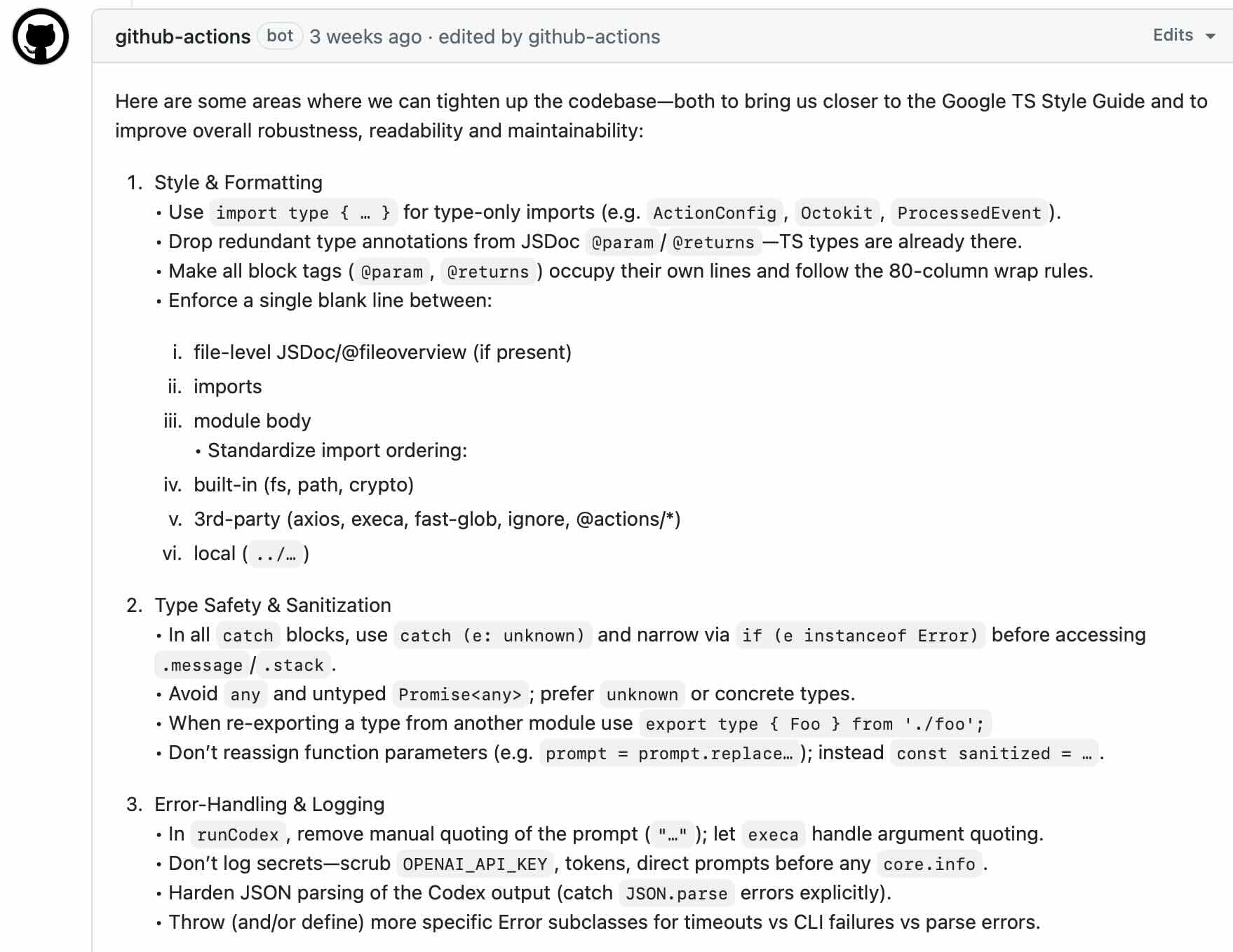
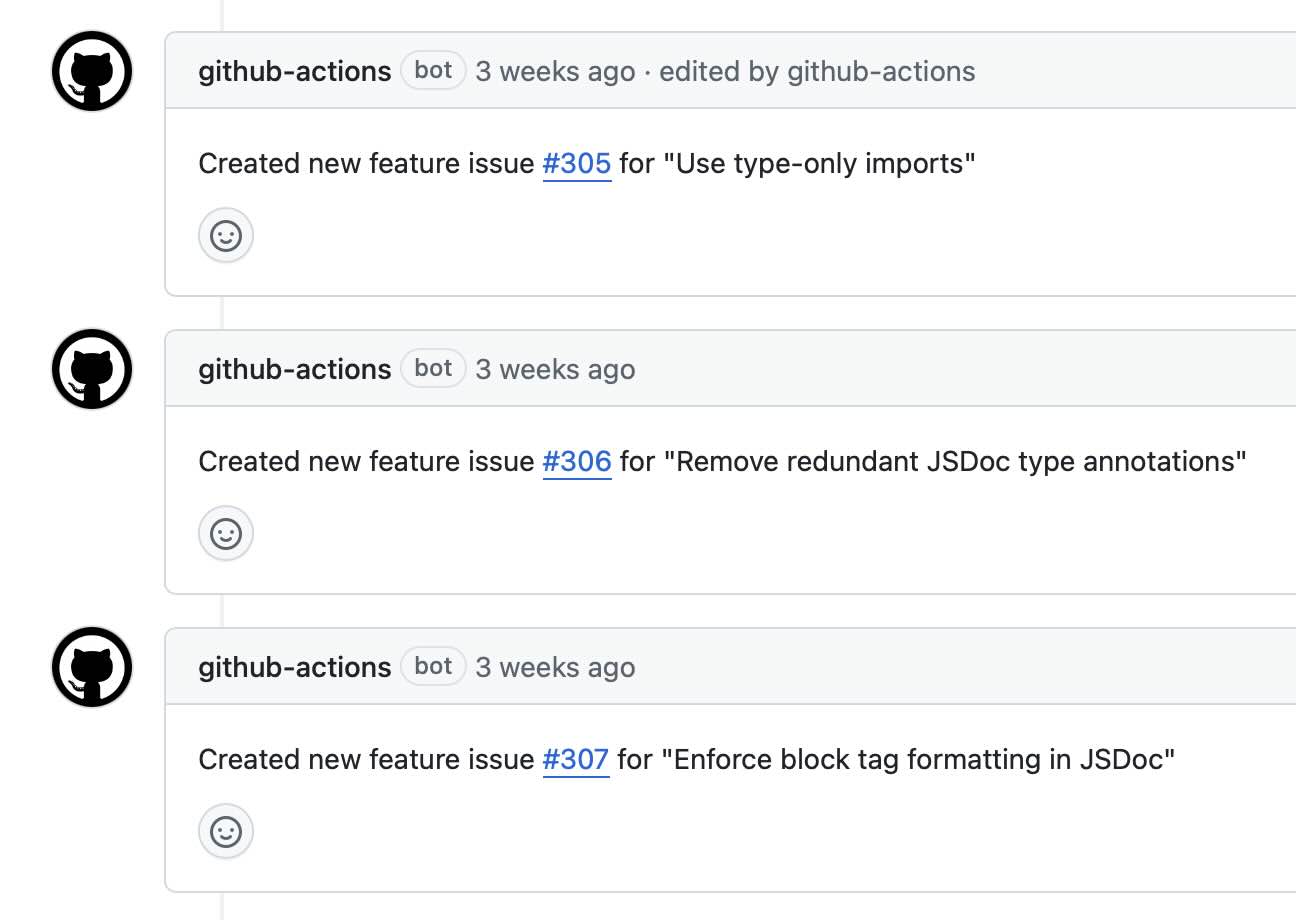
Core Capabilities in the Age of AI

I often find myself thinking: at this point in time, when AI can do so many things so well, what capabilities truly remain essential?
The answer, I believe, is the ability to communicate effectively with AI.
The ability to ask the right questions at critical moments.
Or, put another way, to continually refine prompting to approach a potentially optimal LLM output from multiple angles.
There was a time before LLMs arrived. We are people from that era, and we must reflect on what has changed.
Some ask whether we should use AI, and how we should use it. But what about those for whom LLMs have always existed?
When they enter university, Copilot is already a default feature in VS Code.
Or high school students, just stepping into adolescence, already equipped with tools like Doubao that can answer questions better than their teachers.
Or even younger children, who grow up with ChatGPT as a pressure-free social companion, a friend they can confide in.
All of this feels completely natural.
These natives of the AI era never had the option of not using AI, because its existence is already a given in their environment, an established fact, a known variable in their lives.
I still remember the sense of awe the first time I used GitHub Copilot. Watching it automatically fill in what used to be blank, flowing like water, faster even than my thoughts. I tried to chase it with Vim motions, but the Auto completions were always just ahead of where I was about to reach.
We must believe that Sisyphus is happy.
I know what I am doing.
I also know how this ends.
It’s not a battle that can be won.
Another moment of shock came with my first conversation with GPT-3.5. Science fiction had long imagined many possibilities, but when humanity finally possessed an artificial intelligence that could effortlessly pass the Turing test, the world remained strangely quiet.
As if it were no big deal.
AI has already become part of advanced productivity. Rather than saying it gives you wings, it might be more accurate to say that you, as a human, are becoming the wings of AI. Without you, it cannot take off, but it can still run astonishingly fast. And without it, you are left in the dust, as the rolling wheels of history thunder past, grinding everything beneath them. You are in that dust.
So ask better questions.
Ask about the meaning of the universe. Ask where humanity is headed.
If you can ask a truly good question, you are already very close to the answer.